面臨的痛點
『現有的解決方案讓企業在AI開發與管理上面臨重重挑戰,導致AI難以快速落地,AI平臺架構日益複雜,但仍不夠成熟』

資源管理
GPU資源昂貴,但利用率低
AI實驗難以跟蹤和重現

開發管理
從0到1構建高準確率的AI模型困難
AI模型訓練過程緩慢而冗長

運營管理
將AI部署到雲端、本地和邊緣裝置很複雜
管理AI應用程式執行過程很麻煩
架構痛點
『AI 平臺架構日益複雜,但仍不夠成熟』
基礎建設
『現有的IT基礎建設不適合AI的發展,人工智慧執行在專用硬體加速器上,如GPU,這些硬體加速器的實現和擴充套件支援工具較少。(傳統的CPU計算擁有豐富的軟體堆疊,有許多用於大規模執行應用程式的開發工具)』

企業平臺
最佳的企業級平臺
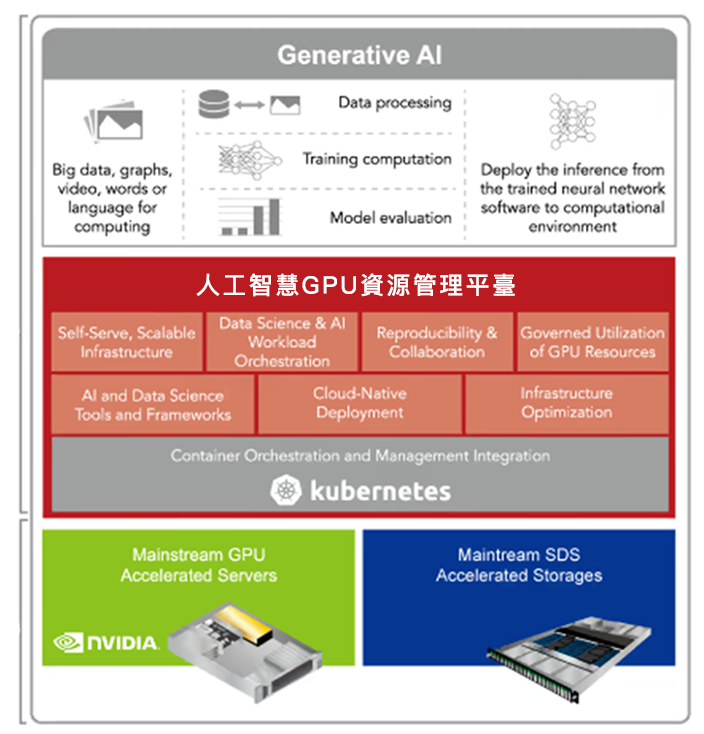
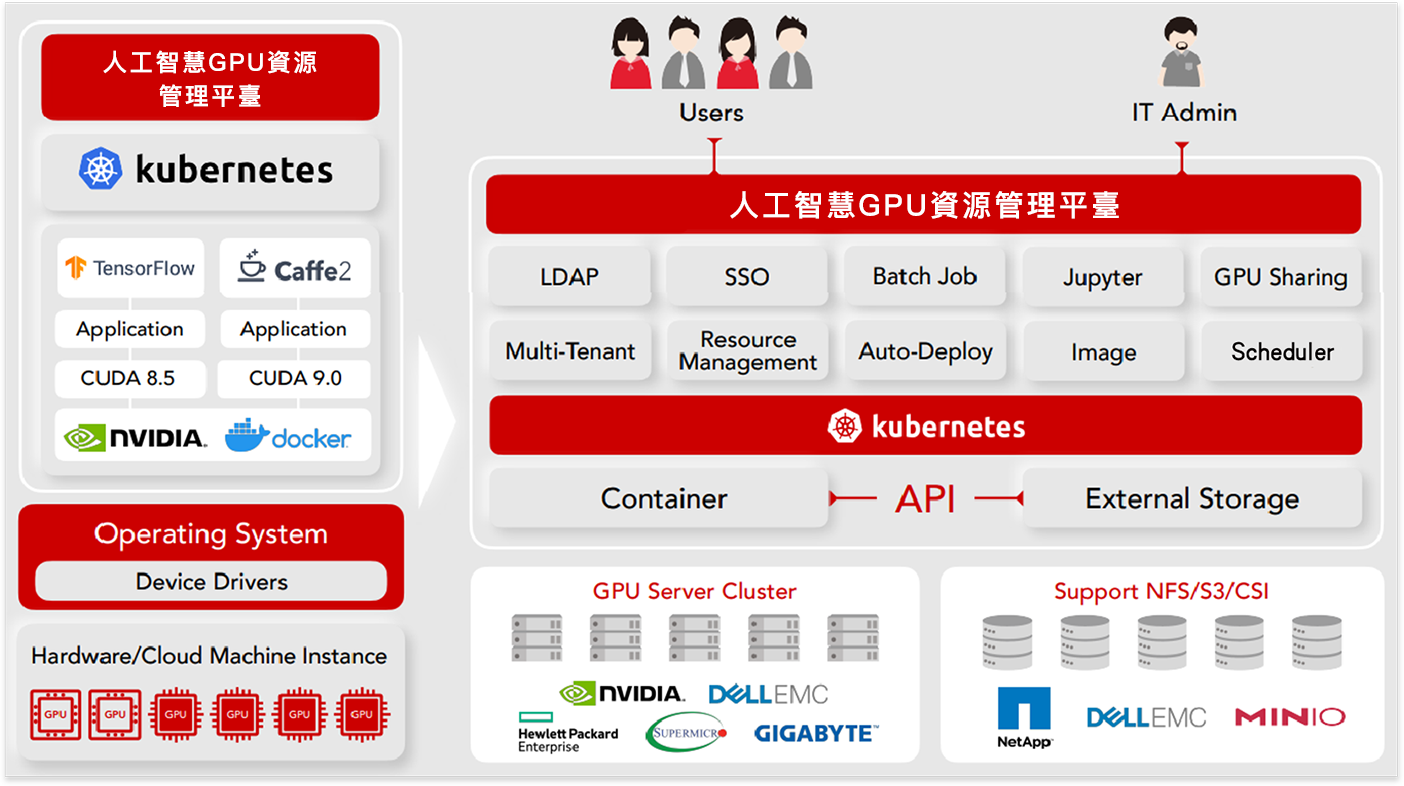
人工智慧GPU資源管理平臺配備了NVIDIA GPU以及企業級MLOps的工作負載編排、自主基礎設施、GPU最佳化,以及透過主流加速伺服器和儲存容器化實現的成本效益平衡。
对数据科学家和AI研究人员
更專注於業務應用開發和研究
隨時啟動人工智慧GPU資源管理平臺,使用配置了最新資料科學工具、 框架和NVIDIA GPU的NVAIE Docker映象。
對IT團隊
企業級安全性、可管理和支援全公司AI應用
人工智慧GPU資源管理平臺已驗證可在K8S上執行,部署在業界領先 的經過NVIDIA認證的系統上。
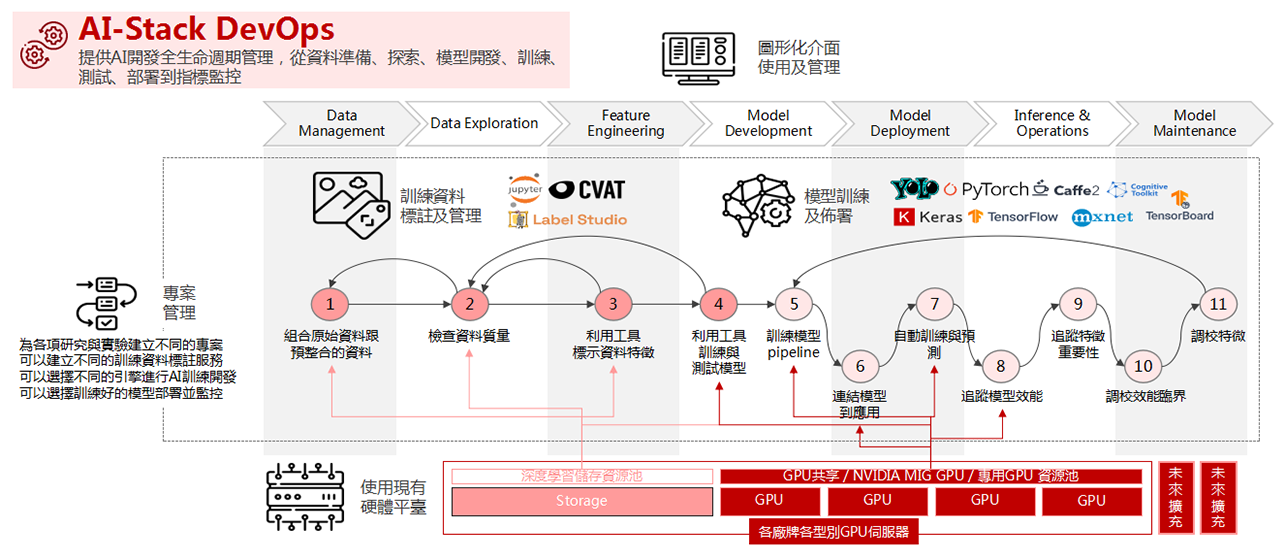
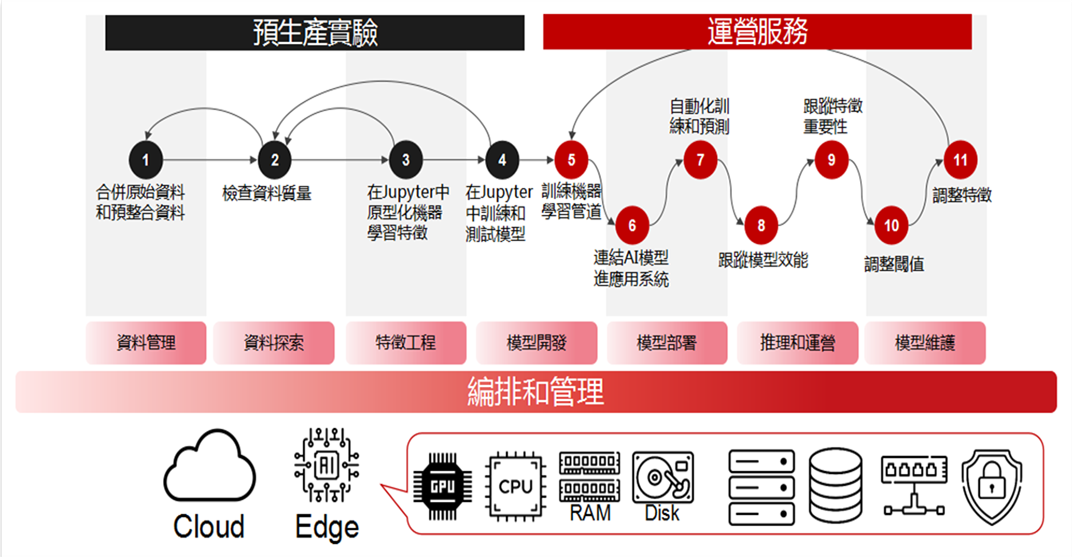
涵蓋需求
『人工智慧GPU資源管理平臺以可擴充套件的方式,涵蓋了所有AI DEVOPS的需求,人工智慧GPU資源管理平臺為AI提供一個基礎,無論是在本地、雲端還是邊緣,均能夠在一個平臺上統合排程管理AI相關資源,並提供所有AI開發階段所需的工具,從模型建立,模型訓練,到生產端進行模型推論』
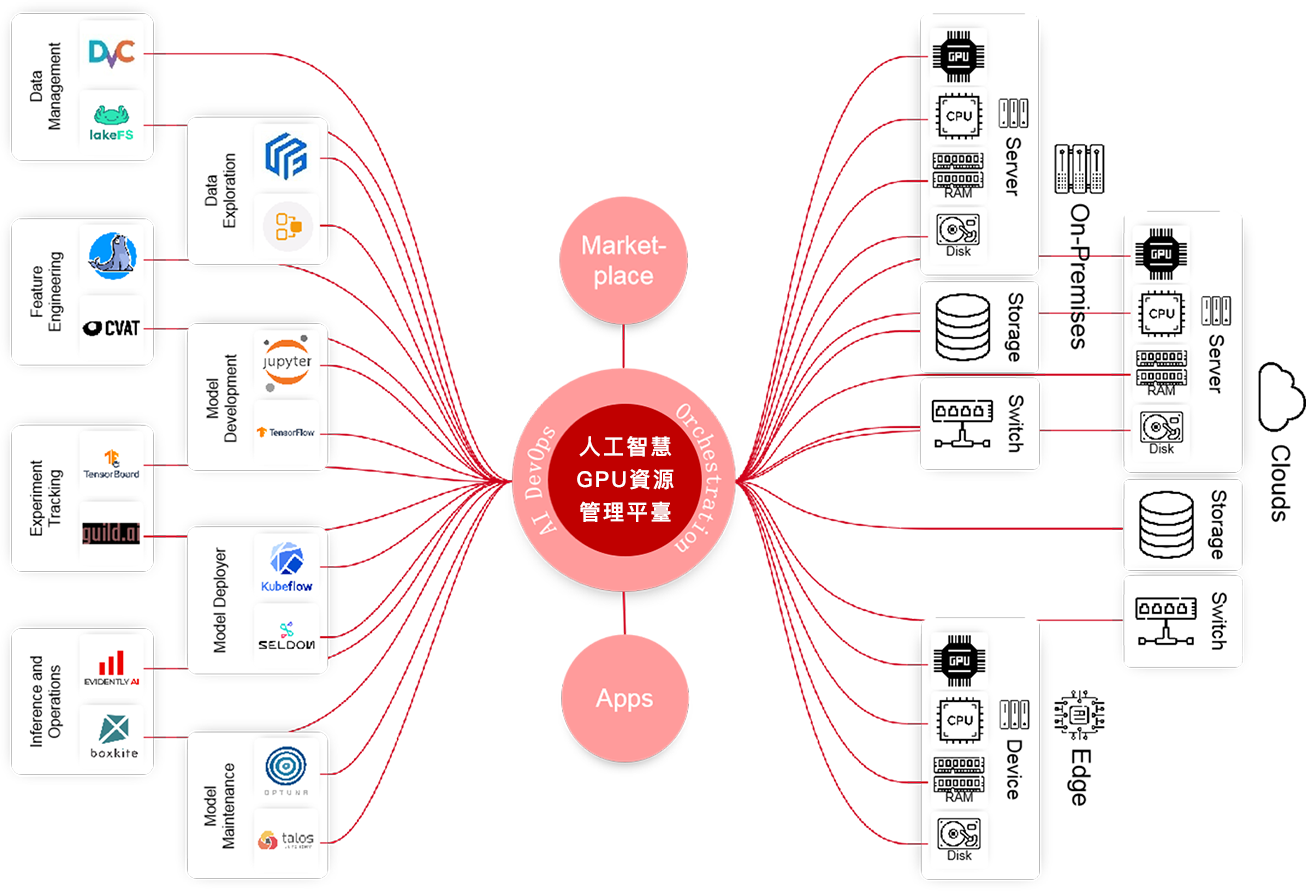
平臺架構
『人工智慧GPU資源管理平臺滿足AI開發生命週期管理』
生命週期管理